
Удаленный вызов процедур
Глава 8
Удаленный вызов процедур
и рандеву
Передача сообщений идеально подходит для программирования фильтров и взаимодействующих равных, поскольку в этих случаях процессы отсылают данные по каналам связи водном направлении. Как было показано, передача сообщений применяется также в программировании клиентов и серверов. Но двусторонний поток данных между клиентом и сервером приходится программировать с помощью двух явных передач сообщений по двум отдельным каналам. Кроме того, каждому клиенту нужен отдельный канал ответа; все это ведет к увеличению числа каналов.
В данной главе рассмотрены две дополнительные программные нотации — удаленный вызов процедур (remote procedure call — RPC) и рандеву, идеально подходящие для программирования взаимодействий типа "клиент-сервер". Они совмещают свойства мониторов и синхронной передачи сообщений Как и при использовании мониторов, модуль или процесс экспортирует операции, а операции запускаются с помощью оператора call. Как и синхронизированная отправка сообщения, выполнение оператора call приостанавливает работу процесса Новизна RPC и рандеву состоит в том, что они работают с двусторонним каналом связи от процесса, вызывающего функцию, к процессу, который обслуживает вызов, и в обратном направлении Вызвавший функцию процесс ждет, пока будет выполнена необходимая операция и возвращены ее результаты.
RPC и рандеву различаются способом обслуживания вызовов операций. Первый способ — для каждой операции объявлять процедуру и для обработки вызова создавать новый процесс (по крайней мере, теоретически). Этот способ называется удаленным вызовом процедуры (RPC), поскольку вызывающий процедуру процесс и ее тело могут находиться на разных машинах. Второй способ — назначить встречу (рандеву) с существующим процессом. Рандеву обслуживается с помощью оператора ввода (приема), который ждет вызова, обрабатывает его и возвращает результаты. (Иногда этот тип взаимодействия называется расширенным рандеву в отличие от простого рандеву, при котором встречаются операторы передачи и приема при синхронной передаче сообщений.)
В разделах 8.1 и 8 2 описаны типичные примеры программной нотации для RPC и рандеву, продемонстрировано их использование. Как упоминалось, эти методы упрощают программирование взаимодействий типа "клиент-сервер". Их можно использовать и при программировании фильтров, но мы увидим, что это трудоемкое занятие, поскольку ни RPC, ни рандеву напрямую не поддерживают асинхронную связь. К счастью, эту проблему можно решить, если объединить RPC, рандеву и асинхронную передачу сообщений в мощный, но достаточно простой язык, представленный в разделе 8.3.
Использование нотаций, их преимущества и недостатки демонстрируются на нескольких примерах В некоторых из них использованы задачи, рассмотренные ранее, что помогает сравнить различные виды передачи сообщений. Некоторые задачи приводятся впервые и демонстрируют применимость RPC и рандеву в программировании взаимодействий типа "клиент-сервер". Например, в разделе 8.4 показано, как реализовать инкапсулированную базу данных и дублирование файлов. В разделах 8 5—8.7 дан обзор механизмов распределенного программирования трех языков. Java (RPC), Ada (рандеву) и SR (совместно используемые примитивы).
284 Часть 2. Распределенное программирование
Следующая диаграмма иллюстрирует взаимодействие между процессом, вызывающим процедуру, и процессом-сервером.

Ось времени проходит по рисунку вниз, волнистые линии показывают ход выполнения процесса. Когда вызывающий процесс доходит до оператора call, он приостанавливается, пока сервер выполняет тело вызванной процедуры. После того как сервер возвратит результаты, вызвавший процесс продолжается.
8.1.1. Синхронизация в модулях
Сам по себе RPC — это механизм взаимодействия. Хотя вызывающий процесс синхронизируется со своим сервером, единственная роль сервера — действовать от имени вызывающего процесса. Теоретически все происходит так же, как если бы вызывающий процесс сам выполнял процедуру, поэтому синхронизация между вызывающим процессом и сервером происходит неявно.
Нужен также способ обеспечивать взаимно исключающий доступ процессов модуля к разделяемым переменным и их синхронизацию. Процессы модуля— это процессы-серверы, выполняющие удаленные вызовы, и фоновые процессы, объявленные в модуле.
Существует два подхода к обеспечению синхронизации в модулях. Первый — считать, что все процессы одного модуля должны выполняться со взаимным исключением, т.е. в любой момент времени может быть активен только один процесс. Этот метод аналогичен неявному исключению, определенному для мониторов, и гарантирует защиту разделяемых переменных от одновременного доступа. Но при этом нужен способ программирования условной синхронизации процессов, для чего можно использовать условные переменные (как в мониторах) или семафоры.
Второй подход — считать, что все процессы выполняются параллельно, и явным образом программировать взаимное исключение и условную синхронизацию. Тогда каждый модуль сам становится параллельной программой, и можно применить любой описанный метод. Например, можно использовать семафоры или локальные мониторы. В действительности, как будет показано в этой главе ниже, можно использовать рандеву (или даже передачу сообщений).
Программа, содержащая модули, выполняется, начиная с кода инициализации каждого из модулей. Коды инициализации разных модулей могут выполняться параллельно при условии,
286 Часть 2. Распределенное программирование
что в них нет удаленных вызовов. Затем запускаются фоновые процессы. Если исключение неявное, то одновременно в модуле выполняется только один фоновый процесс; когда он приостанавливается или завершается, может выполняться другой фоновый процесс. Если процессы модуля выполняются параллельно, то все фоновые процессы модуля могут начинаться одновременно.
У неявной формы исключения есть два преимущества. Первое — модули проще программировать, поскольку разделяемые переменные автоматически защищаются от конфликтов одновременного доступа. Второе — реализация модулей, выполняемых на однопроцессорных машинах, может быть более эффективной. Дело в том, что переключение контекста происходит только в точках входа, возврата или приостановки процедур или процессов, а не в произвольных точках, когда регистры могут содержать результаты промежуточных вычислений.
С другой стороны, предположение о параллельном выполнении процессов является более общим. Параллельное выполнение — это естественная модель для программ, работающих на обычных теперь мультипроцессорах с разделяемой памятью. Кроме того, с помощью параллельной модели выполнения можно реализовать квантование времени, чтобы разделять его между процессами и "обуздывать" неуправляемые процессы (например, зациклившиеся). Это невозможно при использовании исключающей модели выполнения, если только процессы сами не освобождают процессор через разумные промежутки времени, поскольку контекст можно переключить, только когда выполняемый процесс достигает точки выхода или приостановки.
Итак, будем предполагать, что процессы внутри модуля выполняются параллельно, и поэтому необходимо программировать взаимное исключение и условную синхронизацию.
В следующих двух разделах показано, как программировать сервер времени и кэширование в распределенной файловой системе с использованием семафоров.
8.1.2. Сервер времени
Рассмотрим задачу реализации сервера времени — модуля, который обслуживает работу с временными интервалами клиентских процессов из других модулей. Предположим, что в сервере времени определены две видимые операции: get_time и delay. Клиентский процесс получает время суток, вызывая операцию get_time, и блокируется на interval единиц времени с помощью операции delay. Сервер времени также содержит внутренний процесс, который постоянно запускает аппаратный таймер и при возникновении прерывания от таймера увеличивает время суток.
Листинг 8.1 содержит программу модуля сервера времени. Время суток хранится в переменной tod (time of day). Несколько клиентов могут вызывать функции get_time и delay одновременно, поэтому несколько процессов могут одновременно обслуживать вызовы. Такое обслуживание нескольких вызовов операции get_time безопасно для процессов, поскольку они просто считывают значение tod. Но операции delay и tick должны выполняться со взаимным исключением, обрабатывая очередь "уснувших" клиентских процессов napQ. Вместе с тем, в операции delay присваивание значения переменной wake_time может не быть критической секцией, поскольку переменная tod — это единственная разделяемая переменная, которая просто считывается. Кроме того, увеличение tod в процессе Clock также может не быть критической секцией, поскольку только процесс Clock может присваивать значение этой переменной..
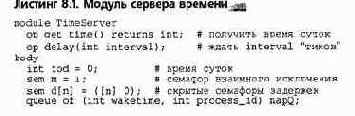

Предполагается, что значение переменной myid в процессе delay является уникальным целым числом в промежутке от 0 до п-1. Оно используется для указания скрытого семафора, на котором приостановлен клиент. После прерывания от часов процесс Clock выполняет цикл проверки очереди napQ; он сигнализирует соответствующему семафору задержки, когда заданный интервал задержки заканчивается.
Может быть несколько процессов, ожидающих одно и то же время запуска, поэтому используется цикл.
8.1.3. Кэширование в распределенной файловой системе
Рассмотрим упрощенную версию задачи, возникающей в распределенных файловых системах и базах данных. Предположим, что прикладные процессы выполняются на рабочей станции, а файлы данных хранятся на файловом сервере. Не будем останавливаться на том, как файлы открываются и закрываются, а сосредоточимся на их чтении и записи. Когда прикладной процесс хочет получить доступ к файлу, он вызывает процедуру read или write влокальном модуле FileCache. Будем считать, что приложения читают и записывают массивы символов (байтов). Иногда это может быть несколько символов, а иногда — тысячи.
Файлы хранятся на диске файлового сервера в блоках фиксированного размера (например, по 1024 байт). Модуль FileServer управляет доступом к блокам диска. Для чтения и записи целых блоков он обеспечивает две операции, readblk и writeblk.
Модуль FileCache кэширует последние считанные блоки данных. Когда приложение запрашивает чтение части файла, модуль FileCache сначала проверяет, есть ли эти данные в его кэш-памяти. Если есть, то он может быстро обработать запрос клиента. Если нет, он должен вызвать процедуру readblk из модуля FileServer для получения блоков диска с запрашиваемыми данными. (Модуль FileCache может производить упреждающее чтение, если определит, что происходят последовательные обращения к файлу. А это бывает часто.)


При условии, что у каждого прикладного процесса есть отдельный модуль FileCache, внутренняя синхронизация в этом модуле не нужна, поскольку в любой момент времени может выполняться только один запрос чтения или записи. Но если несколько прикладных процессов используют один модуль FileCache или в нем есть процесс, который реализует упреждающее чтение, то для обеспечения взаимно исключающего доступа к разделяемой кэш-памяти в этом модуле необходимо использовать семафоры.
В модуле FileServer внутренняя синхронизация необходима, поскольку он совместно используется несколькими модулями FileCache и содержит внутренний процесс Disk-Driver.
В частности, необходимо синхронизировать процессы, обрабатывающие вызовы операций writeblk и readblk, и процесс DiskDriver, чтобы защитить доступ к кэшпамяти дисковых блоков и планировать операции доступа к диску. В листинге 8.2 код синхронизации не показан, но его нетрудно написать, используя методы из главы 4.
8.1.4. Сортирующая сеть из фильтров слияния
Хотя RPC упрощает программирование взаимодействий "клиент-сервер", его неудобно использовать для программирования фильтров и взаимодействующих равных. В этом разделе еще раз рассматривается задача реализации сортирующей сети из фильтров слияния, представленной в разделе 7.2, и показан способ поддержки динамических каналов связи с помощью указателей на операции в других модулях.
Напомним, что фильтр слияния получает два входных потока и производит один выходной. Предполагается, что каждый входной поток отсортирован, и задача фильтра — объединить значения из входных потоков в отсортированный выходной. Как и в разделе 7.2, предположим, что конец входного потока обозначен маркером EOS.
Первая проблема при программировании фильтра слияния с помощью RPC состоит в том, что RPC не поддерживает непосредственное взаимодействие процесс-процесс. Вместо этого в программе нужно явно реализовывать межпроцессное взаимодействие, поскольку для него нет примитивов, аналогичных примитивам для передачи сообщений.
290 Часть 2. Распределенное программирование
Еще одна проблема — связать между собой экземпляры фильтров. Каждый фильтр должен направить свой выходной поток во входной поток другого фильтра, но имена операций, представляющих каналы взаимодействия, являются различными идентификаторами. Таким образом, каждый входной поток должен быть реализован отдельной процедурой. Это затрудняет использование статического именования, поскольку фильтр слияния должен знать символьное имя операции, которую нужно вызвать для передачи выходного значения следующему фильтру.
Намного удобнее использовать динамическое именование, при котором каждому фильтру передается ссылка на операцию, используемую для вывода. Динамическая ссылка представляется мандатом доступа (capability), который можно рассматривать как указатель на операцию.
Листинг 8.3 содержит модуль, реализующий массив фильтров Merge. В первой строке модуля дано глобальное определение типа операций stream, получающих в качестве аргумента одно целое число. Каждый модуль экспортирует две операции, inl и in2. Они обеспечивают входные потоки и могут использоваться другими модулями для получения входных значений. Модули экспортируют третью операцию, initialize, которую вызывает главный модуль (не показан), чтобы передать фильтру мандат доступа к используемому выходному потоку. Например, главный модуль может дать фильтру Merge [ i ] мандат доступа к операции in2 фильтра Merge [ j ] с помощью следующего кода:

Глава 8. Удаленный вызов процедур и рандеву 291
else # v2 == EOS while (vl != EOS)
{ call out(vl); V(emptyl); P(fulll); } call out(EOS); # присоединить маркер конца } end Merge
Остальная часть модуля аналогична процессу Merge (см. листинг 7.2). Переменные vl и v2 соответствуют одноименным переменным в листинге 7.2, а процесс м повторяет действия процесса Merge. Однако процесс М для помещения следующего значения в выходной канал out использует оператор call, а не send. Процесс м для получения следующего числа из соответствующего входного потока использует операции семафора. Внутри модуля неявные серверные процессы, которые обрабатывают вызовы операций inl и in2, являются производителями, а процесс М — потребителем. Эти процессы синхронизируются так же, как процессы производителей и потребителей в листинге 4.3.
Сравнение программ в листингах 8.3 и 7.2 четко показывает недостатки PRC по отношению к передаче сообщений при программировании фильтров. Хотя процессы в обоих листингах похожи, для работы программы 8.3 необходимы дополнительные фрагменты.
В результате программа«работает примерно с такой же производительностью, но, используя RPC, программист должен написать намного больше.
8.1.5. Взаимодействующие равные: обмен значений
RPC можно использовать и для программирования обмена информацией, возникающего при взаимодействии равных процессов. Однако по сравнению с использованием передачи сообщений программы получаются громоздкими. В качестве примера рассмотрим взаимодействие двух процессов из разных модулей, которым необходимо обменять значения. Чтобы связаться с другим модулем, каждый процесс должен использовать RPC, поэтому каждый модуль должен экспортировать процедуру, вызываемую из другого модуля.
В листинге 8.4 показан один из способов программирования обмена значений. Для пересылки значения из одного модуля в другой используется операция deposit. Для реализации обмена каждый из рабочих процессов выполняет два шага: передает значение myvalue в другой модуль, а затем ждет, пока другой процесс не присвоит это значение своей локальной переменной. (Выражение З-i в каждом модуле задает номер модуля, с которым нужно взаимодействовать; например, модуль 1 должен обратиться к модулю с номером 3-1, т.е. 2.) В модулях используется семафор ready; он гарантирует, что рабочий процесс не получит доступ к переменной othervalue до того, как ей будет присвоено значение в операции deposit.
Листинг 8.4. Обмен значений с использованием R PC
module Exchange[i = 1 to 2]
op deposit(int); body
int othervalue;
sem ready =0; # используется для сигнализации proc deposit(other) { # вызывается из другого модуля othervalue = other; # сохранить полученное значение V(ready); # разрешить процессу Worker забрать его }
process Worker { int myvalue; call Exchange[3-i].deposit(myvalue); # отослать другому
292 Часть 2. Распределенное программирование
Р(ready); # ждать получения значения из другого процесса
} end Exchange____________________________________________________________
8.2. Рандеву
Сам по себе RPC обеспечивает только механизм межмодульного взаимодействия. Внутри модуля все равно нужно программировать синхронизацию. Иногда приходится определять дополнительные процессы, чтобы обрабатывать данные, передаваемые с помощью RPC. Это было показано в модуле Merge (см. листинг 8.3).
Рандеву сочетает взаимодействие и синхронизацию. Как и при PRC, клиентский процесс вызывает операцию с помощью оператора call. Но операцию обслуживает уже существующий, а не вновь создаваемый процесс. В частности, процесс-сервер использует оператор ввода, чтобы ожидать и затем действовать в пределах одного вызова. Следовательно, операции обслуживаются по одной, а не параллельно.
Как и в предыдущем разделе, часть модуля с определениями содержит объявления заголовков операций, экспортируемых модулем, но тело модуля теперь состоит из одного процесса, обслуживающего операции. (В следующем разделе это обобщается.) Используются также массивы операций, объявляемые с помощью добавления диапазона значений индекса к имени операции.
8.2.1. Операторы ввода
Предположим, что модуль экспортирует следующую операцию. op opname (типы параметров) ;
Процесс-сервер этого модуля осуществляет рандеву с процессом, вызвавшим операцию op-name, выполняя оператор ввода. Простейший вариант оператора ввода имеет вид:
in opname (параметры) -> S; ni
Область между ключевыми словами in и ni называется защищенной операцией. Защита именует операцию и обеспечивает идентификаторы для ее параметров (если они есть). S обозначает список операторов, обслуживающих вызов операции. Областью видимости параметров является вся защищенная операция, поэтому операторы из S могут считывать и записывать значения параметров.
Оператор ввода приостанавливает работу процесса-сервера до появления хотя бы одного вызова операции opname. Затем процесс выбирает самый старый из ожидающих вызовов, копирует значения его аргументов в параметры, выполняет список операторов S и, наконец, возвращает результирующие параметры вызвавшему процессу.
В этот момент и процесс-сервер, выполняющий in, и клиентский процесс, который вызывал opname, могут продолжать работу.
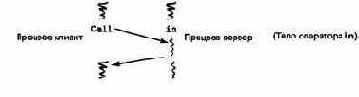
Следующая диаграмма отражает отношения между вызывающим и серверным процессами. Время возрастает в диаграмме сверху вниз, а волнистые линии показывают, когда процесс выполняется.
Глава 8. Удаленный вызов процедур и рандеву 293
Как и при использовании RPC, процесс, достигший оператора call, приостанавливается и возобновляется после того, как процесс-сервер выполнит вызванную операцию. Однако при использовании рандеву сервер является активным процессом, который работает и до, и после обслуживания удаленного вызова. Как было указано выше, сервер также задерживается, достигая оператора in, если нет ожидающих выполнения вызовов. Читателю было бы полезно сравнить приведенную диаграмму с аналогичной диаграммой для RPC.
Приведенный выше оператор ввода обслуживает одну операцию. Как сказано в разделе 7.6, защищенное взаимодействие полезно тем, что позволяет процессу ожидать выполнения одного из нескольких условий. Можно объединить рандеву и защищенное взаимодействие, используя общую форму оператора ввода.
in opi(параметры) and В1. by ei -> Si;
[] ...
[] оръ(параметрып) and В„ by en
-> Sn;
ni
Каждая ветвь оператора in является защищенной операцией. Часть кода перед символами -> называется защитой; каждое Si обозначает последовательность операторов. Защита содержит имя операции, ее параметры, необязательное условие синхронизации and Bj. и необязательное выражение планирования by e^.. В этих условиях и выражениях могут использоваться параметры операции.
В языке Ada (раздел 8.6) поддержка рандеву реализована с помощью оператора accept, а защищенное взаимодействие— оператора select. Оператор accept очень похож на in в простой форме, а оператор select — на общую форму in. Но in в общей форме предоставляет больше возможностей, чем select, поскольку в операторе select нельзя использовать аргументы операции и выражения планирования.
Эти различия обсуждаются в разделе 8.6.
Защита в операторе ввода пропускает, если была вызвана операция и соответствующее условие синхронизации истинно (или отсутствует). Область видимости параметров включает всю защищенную операцию, поэтому условие синхронизации может зависеть от значений параметров, т.е. от значений аргументов в вызове операции. Таким образом, один вызов операции может привести к тому, что защита пропустит, а другой — что не пропустит.
Выполнение оператора in приостанавливает работу процесса, пока не пропустит какая-нибудь защита. Если пропускают несколько защит (и нет условий планирования), то оператор in обслуживает первый (по времени) вызов, пропускаемый защитой. Аргументы этого вызова копируются в параметры, и затем выполняется соответствующий список операторов. По завершении операторов результирующие параметры и возвращаемое значение (если есть) возвращаются процессу, вызвавшему операцию. В этот момент операторы call и in завершаются.
Выражение планирования используется для изменения порядка обработки вызовов, используемого по умолчанию (первым обслуживается самый старый вызов). Если есть несколько вызовов, пропускаемых защитой, то первым обслуживается самый старый вызов, у которого выражение планирования имеет минимальное значение. Как и условие синхронизации, выражение планирования может ссылаться на параметры операции, и, следовательно, его значение может зависеть от аргументов вызова операции. В действительности, если в выражении планирования используются только локальные переменные, его значение одинаково для всех вызовов и не влияет на порядок обслуживания вызовов.
Как мы увидим далее, условия синхронизации и выражения планирования очень полезны. Они используются не только в рандеву, но и в синхронной и асинхронной передаче сообщений. Например, можно позволить операторам receive задействовать свои параметры, и многие библиотеки передачи сообщений обеспечивают средства для управления порядком получения сообщений.
Например, в библиотеке MPI получатель сообщения может определять отправителя и тип сообщения.
294 Часть 2 Распределенное программирование
8.2.2. Примеры взаимодействий типа "клиент-сервер"
В данном разделе представлены небольшие примеры, иллюстрирующие использование операторов ввода. Вернемся к задаче реализации кольцевого буфера. Нам нужен процесс, который имеет локальный буфер на п элементов и обслуживает две операции: deposit и fetch. Вызывая операцию deposit, производитель помещает элемент в буфер, а с помощью операции fetch потребитель извлекает элемент из буфера. Как обычно, операция deposit должна задерживаться, если в буфере уже есть n элементов, а операция fetch — пока в буфере не появится хотя бы один элемент.
Листинг 8.5 содержит модуль, реализующий кольцевой буфер. Процесс Buffer объявляет локальные переменные, которые представляют буфер, и затем циклически выполняет оператор ввода. На каждой итерации процесс Buffer ждет вызова операции deposit или fetch. Условия синхронизации в защитах обеспечивают необходимые задержки операций deposit и fetch.

Полезно сравнить процесс Buffer и монитор в листинге 5.3. Интерфейсы клиентских процессов и результаты вызова операций deposit и fetch у них одинаковые, а реализации совершенно разные. Тела процедур в реализации монитора превратились в список операторов в операторе ввода, и условие синхронизации выражается с помощью логических выражений, а не условных переменных.
Еще один пример: листинг 8.6 содержит модуль, реализующий централизованное решение задачи об обедающих философах. Структура процесса Waiter аналогична структуре процесса Buffer. Вызов операции getf orks может быть обслужен, если ни один из соседей не ест, а вызов операции relforks— всегда. Философ передает свой индекс i процессу Waiter, который использует этот индекс в условии синхронизации защиты для getf orks. Предполагается, что в этой защите вызовы функций left (i) и right (i) возвращают индексы соседей слева и справа философа Philosopher [ i ].


______________________________________________________________________________________________________________________________________________________________
Листинг8. 7 содержит модуль сервера времени, по назначению аналогичный модулю влистинге 8.1. Операции get_time и delay экспортируются для клиентов, a tick— для обработчика прерывания часов. В листинге 8.7 аргументом операции delay является время, в которое должен быть запущен клиентский процесс. Клиентский интерфейс данного модуля несколько отличается от интерфейса, приведенного в листинге 8.1. Клиентские процессы должны передавать время запуска, чтобы для управления порядком обслуживания вызовов delay можно было использовать условие синхронизации. В программе с применением рандеву процесс Timer может не поддерживать очередь приостановленных процессов; вместо этого приостановленными являются те процессы, время запуска которых еще не пришло. (Их вызовы остаются в очереди канала delay.)


8.2.3. Сортирующая сеть из фильтров слияния
Снова рассмотрим задачу реализации сортирующей сети с использованием фильтров слияния и решим ее, используя механизм рандеву. Есть два пути. Первый — использовать два вида процессов: один для реализации фильтров слияния и один для реализации буферов взаимодействия. Между каждой парой фильтров поместим процесс-буфер, реализованный в листинге 8.5. Каждый процесс-фильтр будет извлекать новые значения из буферов между этим процессом и его предшественниками в сети фильтров, сливать их и помещать свой выход в буфер между ним и следующим фильтром сети.
Аналогично описанному сети фильтров реализованы в операционной системе UNIX, где буферы обеспечиваются так называемыми каналами UNIX. Фильтр получает входные значения, читая из входного канала (или файла), а отсылает результаты, записывая их в выходной канал (или файл). Каналы реализуются не процессами; они больше похожи на мониторы, но пррцессы фильтров используют их таким же образом.
Второй путь для программирования фильтров — использовать операторы ввода для извлечения входных значений и операторы call для передачи выходных.
При таком подходе фильтры взаимодействуют между собой напрямую. В листинге 8.9 показан массив фильтров для сортировки слиянием, запрограммированных по второму методу. Как и в листинге 8.3, фильтр получает значения из двух входных потоков и отсылает результаты в выходной поток. Здесь также используется динамическое именование, чтобы с помощью операции initialize дать каждому процессу мандат доступа к выходному потоку, который он должен использовать. Этот поток связан со входным потоком другого элемента массива модулей Merge. Несмотря на эти общие черты, программы в листингах 8.3 и 8.8 совершенно разные, поскольку рандеву, в отличие от RPC, поддерживает прямую связь между процессами. Поэтому для программирования процессов-фильтров легче использовать рандеву


Процесс в листинге 8.9 похож на процесс из программы в листинге 7.2, который был запрограммирован с помощью асинхронной передачи сообщений. Операторы взаимодействия запрограммированы по-разному, но находятся в одних и тех же местах программ. Однако, поскольку оператор call является блокирующим, выполнение процесса гораздо теснее связано с рандеву, чем с асинхронной передачей сообщений. В частности, разные процессы Filter будут выполняться примерно с одинаковой скоростью, поскольку каждый поток будет всегда содержать не больше одного числа. (Процесс-фильтр не может вывести в поток второе значение, пока другой фильтр не получит первое.)
8.2.4. Взаимодействующие равные: обмен значений
Вернемся к задаче о процессах из двух модулей, которые обмениваются значениями переменных. Из листинга 8.4 видно, насколько сложно решить эту задачу с использованием RPC. Упростить решение можно, используя рандеву, хотя это хуже, чем передача сообщений.
Используя рандеву, процессы могут связываться между собой напрямую. Но, если оба процесса сделают вызовы одновременно, они заблокируют друг друга. Аналогично процессы одновременно не могут выполнять операторы in. Таким образом, решение должно быть асимметричным; один процесс должен выполнить оператор call и затем in, а другой — сначала in, а затем call.Это решение представлено в листинге 8.10. Требование асимметрии процессов приводит к появлению оператора i f в каждом процессе Worker. (Асимметричное __ решение можно получить, имитируя программу с RPC в листинге 8.4, но это еще сложнее.)

298 Часть 2. Распределенное программирование